
.png)
Here’s something I wasn’t proud to realize about myself.
I run a Revenue Activation company. We built the category. Our thesis: every revenue team has buried capacity, and five levers - Ramp, In-Flow, Content, Coaching, Proof - determine whether it stays buried or gets released. AI owns the work around the conversation. Humans own the conversation. We sell this to CROs, VPs of Enablement, and CTOs every week.
And every morning, I was manually checking four dashboards, copying context from one tool to another, and carrying information between meetings in my head.
I was the router.
Every piece of context in the company - pipeline data, customer risk signals, competitive intelligence, product status, hiring updates — flowed through me. Not because I’m a control freak. Because the systems weren’t connected. I was the integration layer. The human middleware.
That’s the exact problem Revenue Activation solves for our customers. Reps spending 70% of their time on non-selling work - that’s an In-Flow constraint. Managers coaching after the deal is decided - that’s a Coaching Precision failure. Content in storage, not in flow - that’s Content Velocity capped. The human doing the machine’s job.
I was my own worst case study.
The Honest Diagnosis
I sat down and ran the same diagnostic on myself that we run on customers. Not the product. The operating model.
The finding: I was AI-native in exploration. My Claude Projects folder had twenty experiments. My Codex workspace had agent prototypes. I’d built a competitive intelligence scanner, a video processor, a strategy notebook. I was exploring AI constantly.
I was not AI-native in operating cadence. None of these experiments ran without me. None of them produced artifacts I could trust without checking. None of them connected to each other.
Idea surplus. Action deficit.
The harder truth: my founder workflows didn’t mirror my product thesis. Revenue Activation means intelligence flows to the user at the moment of need, in the flow of work, without them asking. My own intelligence was trapped in chat windows, experiment folders, and my memory. I was selling activation while operating in storage mode.
If I couldn’t build a system that ran for me, I had no business telling customers they needed one.
So I scored myself against my own framework. Five levers. Ramp Acceleration — not relevant, I’m not a new hire. In-Flow Activation - broken. I was leaving my workflow constantly to assemble context. Content Velocity - broken. I couldn’t find my own competitive intel without digging through folders. Coaching Precision - not applicable to the CEO. Revenue Proof - broken. I couldn’t trace which of my actions moved which deals.
The CEO of a Revenue Activation company, capped on three of his own five levers.
That’s when I stopped exploring and started building.
Five Loops, One System
I built five operating loops. Not all at once. In sequence. Each one layered on the infrastructure of the previous one. The principle: don’t start Loop N+1 until Loop N is scoring well.
Here’s what they are, what they produce, and what I learned from each.
Loop 1: The Morning Memo
Every morning at 7 AM, I receive a one-page memo. Pipeline truth. Top customer risks. Product blockers. Hiring status. Decisions needed today.
Before this loop, I checked HubSpot, Linear, a revenue spreadsheet, and Slack. Four tools. Twenty minutes. By the time I’d assembled the picture, I’d lost the first hour of my day to context assembly - the exact thing we tell reps is killing their capacity.
Building it required wiring three data sources to MCP: CRM pipeline data, project management status, and revenue metrics. The skill pulls from all three, synthesizes, and produces the memo.
The first week I ran it manually and scored every output. Was it accurate? Was it useful? Did it save time? Did it surface something I didn’t already know?
What I learned: The first three memos were mediocre. They summarized data I could see in dashboards. They didn’t interpret. By day four, after I’d refined the skill with better prompts about what “decisions needed today” actually meant, the memo started flagging things I would have missed. A deal that had gone silent for 12 days. A product milestone that was blocking a customer commitment. A hiring candidate whose timeline conflicted with a sprint dependency.
That’s when the loop earned trust.
Now I read the brief instead of checking four dashboards. Twenty minutes of context assembly became two minutes of reading. That’s not productivity. That’s capacity.
Loop 2: Call Prep on Autopilot
Before every meaningful external meeting, I receive a prep brief. Account context. Recent deal activity. Last call summary. Competitive landscape for this specific account. Suggested talking points.
This is literally what our product does for sales reps. So I built it for myself first.
The trigger: calendar event with an external attendee, two hours before the meeting. The skill pulls CRM data, recent interactions, and relevant content. It assembles a brief.
What I learned: The first five briefs were hit-or-miss. Some were excellent — they surfaced a competitive mention from the last call that I’d forgotten. Others were generic summaries that told me things I already knew.
The fix was specificity. I stopped asking for “account context” and started asking for “what changed since the last interaction, what risks surfaced, and what one thing should I absolutely not forget to mention.” The output quality jumped immediately.
The lesson: the quality of the loop is determined by the quality of the question you teach it to ask. Generic instructions produce generic output. Specific instructions produce intelligence.
This loop also gave me a product insight. Our reps were going to have the same experience - generic briefs until the prompts were refined. That meant we needed better default prompts in the product, not just better infrastructure. I wouldn’t have known that without feeling it myself.
Loop 3: Post-Call Commitments
After every important call, I receive a structured artifact: recap, decisions made, owners, deadlines, and suggested follow-up actions.
Before this loop, I had two options: spend 15–20 minutes writing the recap myself, or don’t write it at all and lose the commitments to memory.
The honest answer is that I chose option two more often than I’d like to admit. Commitments lived in my head until they surfaced again - sometimes in the next meeting, sometimes too late.
The loop takes the transcript, extracts the structured commitments, and presents them for my review. I approve, edit, or reject. Two minutes instead of twenty. But more importantly: nothing gets lost.
What I learned: The approval step is essential. I tried running it fully automated for a week. The recaps were 80% right. But the 20% that were wrong - a misattributed action item, a deadline that was tentative not committed, a decision that was actually still open - would have been embarrassing if sent. Human-in-the-loop on write-back is non-negotiable until trust is above 95%.
This is the same principle we build into the product: AI drafts, human approves. The 16/16/27 split. The loop made me believe it more deeply because I felt what happens when you skip the human check.
Loop 4: Voice of Customer
Every Friday, I receive a weekly synthesis: pain points from customer calls, feature requests with frequency, churn signals, competitive mentions, and objection patterns. All from real data.
Before this loop, our product reviews started with anecdotal retelling. “I heard from a customer that...” “Someone mentioned...” The loudest voice in the room shaped the roadmap, not the pattern in the data.
This loop required Loops 2 and 3 to be running first - because it aggregates across call transcripts, support tickets, and CRM notes. Without the upstream data flowing, there’s nothing to synthesize.
What I learned: The first weekly synthesis confirmed something we suspected but couldn’t prove: security and compliance concerns were appearing in more than half our active deals. Not as the primary objection - as a secondary blocker that slowed deals by 3–4 weeks. We didn’t see this in anecdotal retelling because reps reported the primary objection, not the secondary drag.
The pattern was invisible in stories. It was obvious in data.
Product reviews now start with the VoC memo. The conversation shifted from “I think customers want X” to “the data shows X appeared in 4 of 7 calls this week.” That’s a different quality of decision-making.
Loop 5: Board Prep
For investor updates, the agent assembles all the evidence: metrics, pipeline, customer health, product progress, competitive position. I write the narrative.
Board prep used to take me two days. Gathering data from six sources, formatting it, making sure the numbers matched, building the slides. Most of the time was data assembly, not thinking.
Now the loop produces a structured evidence package. The data is there. The charts are drafted. The customer signals are summarized. My job is the 90 minutes of narrative - the story of what happened, what it means, and what we’re doing about it. The part only I can do.
What I learned: The agent is surprisingly good at identifying tensions in the data that I should address proactively. “Pipeline is up 30% but close rate dropped 5% - this needs a narrative.” I would have seen both numbers. I might not have connected them in time to have the answer ready before the board asked.
Board prep dropped from two days to half a day. But the more important change: the quality of my narrative improved because I spent the time thinking instead of assembling.
The Bonus: Adversarial Decisions
Not everything should be a loop. Some decisions are non-repeatable, high-judgment calls. Pricing changes. Roadmap bets. Partnership decisions. Hiring trade-offs.
For these, I built a different structure. Three agents, run in parallel:
Agent 1: Build the strongest case FOR the decision.
Agent 2: Build the strongest case AGAINST the decision.
Agent 3: Identify what I’d need to believe for each option to be the right one.
I review all three in 15 minutes. This replaced “let me think about it over the weekend” with structured analysis on demand.
What I learned: Agent 3 is the most valuable. Not because it gives me the answer - it doesn’t. Because it surfaces the assumptions I’m making without realizing it. “For Option A to be right, you need to believe the market will consolidate within 18 months.” Do I believe that? Now I can test the assumption instead of acting on it unconsciously.
The best use of AI in decision-making is not to make the decision. It’s to make the assumptions visible.
What Actually Changed
Here’s the honest scorecard after running these loops for several weeks:
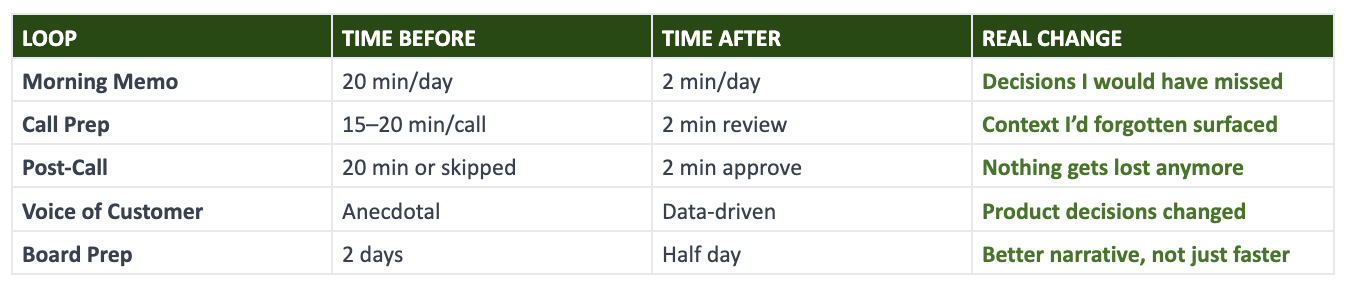
The time savings are real but not the point. The point is what I do with the time.
I’m not faster at checking dashboards. I don’t check them anymore. I’m not faster at writing recaps. The system writes them. I’m not faster at assembling data for the board. The loop assembles it.
The time went from assembly to judgment. That’s the capacity shift.
Revenue Activation language for what happened to me: In-Flow is fixed - intelligence comes to me, I don’t go hunting for it. Revenue Proof is emerging - I can trace which loop surfaced which insight that moved which decision. Content Velocity is solved - the right context surfaces for the right meeting without me searching. Three levers, uncapped. Without adding headcount. Without adding tools. By building the system.
What I Got Wrong
Building in public means publishing the failures.
I tried to build all five loops at once. Failed in the first week. The data layer wasn’t ready. Loop 4 depends on Loop 3 which depends on Loop 2 which depends on Loop 1’s MCP wiring. Sequencing matters. Build the foundation, then the building.
I over-automated Loop 3 before it was ready. Turned off human approval for a week. The recaps were mostly right. But “mostly right” in a post-call commitment email is worse than not sending one at all. Turned approval back on. Haven’t turned it off again.
I kept adding tools instead of deepening loops. Cursor, Codex, Claude Code, Linear Triage, Notion AI, Granola. At one point I had seven AI tools running and none of them connected. That’s the same stack fragmentation problem our customers have. I cut back to three: Claude Code for building, Codex for background tasks, one meeting tool for transcripts. Fewer tools, deeper loops.
The engineering dependencies are real. Three of my five loops are limited by write-back tools that haven’t shipped yet. The system can read from CRM but can’t write. It can generate a DSR but can’t create the page. Read-only intelligence is useful. Read-write intelligence is transformational. The gap between them is an engineering sprint, but it’s the sprint that matters most.
The Meta-Lesson
Here’s what I didn’t expect to learn.
Building these loops for myself didn’t just make me more productive. It made me a better product leader. Every friction point I hit is a product insight. Every loop that failed taught me something about what our customers will experience.
When the Call Prep brief was generic, I knew our default prompts needed work. When the Post-Call commitments were 80% right, I knew human-in-the-loop wasn’t optional. When the VoC synthesis surfaced a pattern nobody had mentioned, I knew cross-deal intelligence was more valuable than individual deal intelligence.
The founder’s operating system becomes the company’s operating system.
That’s the real argument for CEOs building their own loops. Not because it saves you time. Because the system you build for yourself reveals what the product should do for everyone.
What an AI-Native CEO Actually Looks Like
It’s not someone who uses AI tools. Every CEO uses AI tools now.
It’s someone who has rebuilt their operating cadence around AI loops that run whether they’re paying attention or not. Who receives intelligence instead of assembling it. Who spends their time on judgment instead of context.
That doesn’t require building everything yourself. It requires building SOMETHING yourself. One loop. Prove it works. Score it honestly. Then build the next one.
The principle I now tell every CEO I talk to:
Stop using AI as a productivity tool. Start running your company through trusted agent loops. The difference between those two sentences is the difference between using electricity and rewiring the building.
I’m not done. Loop 3 is waiting for write-back tools. Loop 4 needs more data to produce reliable patterns. Loop 5 hasn’t been tested on a real board cycle yet. The system is 60% built.
But 60% is enough to know: the old operating model - CEO as router, CEO as integration layer, CEO as the person who carries context between meetings - is over. Not because I decided it was over. Because I built something better and can’t go back.
That’s Revenue Activation. Not as a pitch. Not as a thesis. As something I built, scored, broke, fixed, and now run every day at a 44-person company that competes with teams twenty times its size.
We built the category because we needed it. Then we built the product because our customers needed it. Then I built the loops because I needed them.
Your move.
Sreedhar Peddineni is the CEO and co-founder of GTM Buddy, a Revenue Activation platform. He is a three-time category creator, previously co-founding Gainsight, which defined the Customer Success category.


.png)
.avif)
